Software Process From First Principles
“New software processes do not just emerge out of thin air; they evolve in response to a palpable need”
Software Architecture In Practice, Third Edition
1. Preliminary Throat Clearing
Is there something wrong with the way we think about software process?
Traditional software processes are often couched in dichotomies: heavy vs agile, bureaucratic vs lightweight, corporate-y vs start-up-y, oppressive vs liberating. Yet dichotomies have and always will obscure gradations of difference and damage our ability for nuanced thinking.
Because there is widespread lack of nuance regarding available software processes, teams often choose processes which are incoherent or inadequate for their situation, team, or organization. Processes are selected by fiat and fashion rather than by their ability to address specific needs.
Even worse, the average person making a process decision has no idea why processes exist or no deep knowledge about what other processes are available to them. This leads them to choose a process because it was easy rather than because it was simple. This often means the process selected is either mis-implemented, partially implemented, or mis-selected relative to another available process.
In what follows I hope to dig up some of the nuance that belongs in these discussions. I’ll start by explaining how one just-so-story – the rise of agile processes – is not only deeply incorrect but obscures the rich history of our industry. Having done this, we’ll rediscover the need for process by starting from first principles. Next, we’ll identify four key concerns that any useful process must credibly address. Finally, we’ll wrap it up and I’ll recommend a few exercises for the intrigued reader.
2. A Just-so Story
If we were to trace the history of software process as it appears in the minds of many people and in the introductions to many books, it would look something like the following:

This seductive image has been wildly successful in selling agile practices, but how does it stack up against the real history? The following is my attempt to trace the historical influence of processes on each other:
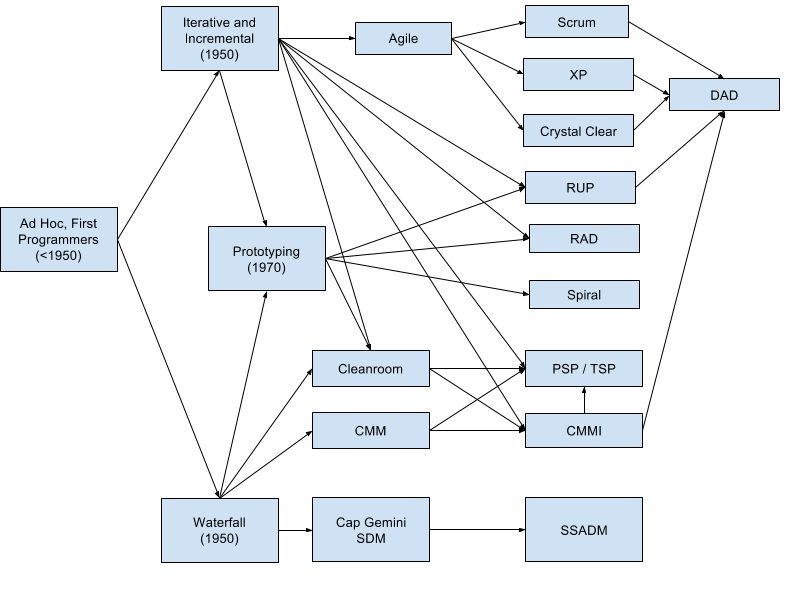
I’m not an expert per se, so this graphic is likely incomplete and contains inaccuracies, but it’s enough to demonstrate my point: before and after agile there was clearly a lot more going on than just “Waterfall”.
Where did this explosion of processes and process frameworks come from? Returning to the opening quote, these processes did not simply emerge, fully formed, out of thin air. Each and every one evolved in response to someone’s palpable needs. Some parts of the software industry need to move fast above all else. Other parts of the software industry need to produce few to no defects above all else. Yet other parts need to distribute work amongst large teams, and others are a complex blend of many needs.
The point is that there are as many potential software processes as companies producing software. The processes we have are the result of individuals in a specific part of the industry attempting to distill what has worked well for them in order to benefit the industry as a whole. The available processes are not gospel, they are a distillation of general solutions that you might be able to adapt to your specific problems. Like the individuals who developed these processes, the specifics of your circumstance are probably unique, however the general problems you’ll face are not.
3. Software Process From First Principles
So why assemble and follow a software development process?
Typically, the decision to use a process is motivated in reaction to a failure. More often than not, it takes several failures before we are willing to throw up our hands and either help ourselves or search for outside help.
Therefore, let us assume that we assemble and follow processes because we want to succeed. So, why do we fail without a process?
We can informally demonstrate the answer with a thought experiment: Assuming time and budget are your two criteria for success, we can build a quick graph:
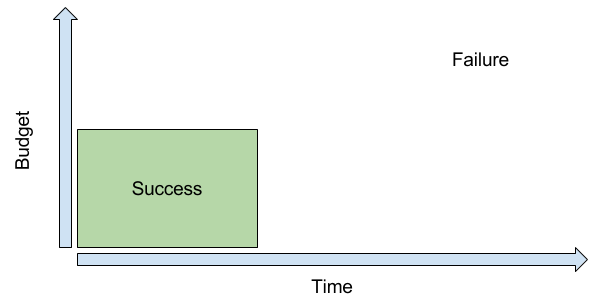
The square labeled “Success” contains all the time and budget combinations that would be considered successful for our project. In the bottom left of the square, we would take a no-cost, immediate solution. At the top right of the square, we would also (more reluctantly) accept a maximum time and maximum budget outcome. Everything outside of this square represents a failure – either the project took too long or it cost too much.
Now pick a random time and a random budget? Does it fall within the success area or the failure area?
From this graph, we can easily see that our random point is far more likely to land in the failure area than in the success area simply because the failure area is larger. There are more ways to exceed time and budget than to stay within them.
For real-world projects, the situation is typically even worse as time and budget are usually only two of many things we care about. For example, we also care about things like customer satisfaction, revenue, security, reliability, etc. This means we’re actually trying to optimize within a complex, multi-dimensional outcome space. If we view a lack of process as equivalent to randomly selecting a point from this outcome space, then we can see that without a process we are far more likely to fail than to succeed.
If we’re ever going to improve our odds, then we need something better than random sampling. We want a repeatable way to guide our projects to success and away from failure. This is where process comes in.
4. The Four Reasons for Process
If you were a captain and you wanted to steer your ship to port, you could probably get there if you knew what to avoid based on the experience of yourself, your crew, and the sailors that came before you. If we had to boil it down to a few things we might say: We have to know where we’re going, the crew has to work together to get us there, we have to track our course along the way, and we have to avoid rocks and other disasters.
Software is no different, we can often get pretty far just by knowing what to avoid. From my fairly extensive reading on this, it seems like processes really only exist to steer teams away from four common failure sources:
- Human forgetfulness
- Human fallibility
- Knowledge fragmentation in teams and organizations
- Unmitigated avoidable risks
This would mean that a successful process would do the following things:
- Augment memory
- Correct human error
- Unite fragmented knowledge
- Manage risk
Each of these must be addressed at every phase of any project. The severity of each problem will, of course, differ from project to project. This project-specific difference will determine the practices you choose to adopt as well as their level of formality.
So let’s go through these one by one. Along the way, you should be able to see that your team and/or organization can easily assemble a set of practices suitable to your environment. This self-assembled set of practices would then be your “process”. You should also realize, you already have some sort of process – it just might not be documented or very good.
4.1. Augment memory
Every software project consists of scores of details – requirements, business rules, open questions, design details, bugs, etc. This volume of details strains even the best memories. Furthermore, these details are changing all the time as people have conversations, decisions are made, and outside forces arise.
Therefore, it is foolhardy to think any person or persons can or should be expected to remember everything about a project. Relying on human memory is a formula for things falling through cracks, and this can and often does lead to disaster.
Luckily for us late humans, we have writing and computers. Both excellent tools for supplementing our inadequate memories. Furthermore, we’re software engineers, so if a tool doesn’t exist we can invent it! An effective team should create forms, documents, and tools for memory augmentation judiciously, and regularly update them as they identify possible improvements. Forms and documents are cheap and quick to create and test, tools are usually expensive and slow to implement – so the decision of what to try first should be based on cost-benefit analysis of your situation.
Some tools for memory augmentation: Ticketing, product backlog, issue and project tracking, open question tracking, requirements documentation, architecture documentation, meeting notes/minutes, code documentation.
4.2. Correct human error
Decades of software engineering economics has fairly conclusively demonstrated that even the best engineers make mistakes. Not only that, they make a lot of mistakes – 50-100 defects/KLOC in the average case. That’s 1 defect for every 10-20 lines you type.
Even worse, this situation doesn’t show any signs of improving in the immediate future.
Many engineers fix defects along the way with unit-testing, compilers, and static analysis tools. However, no single method is capable of finding more than roughly 75% of the defects you’ve injected, and even rates that good are typically extremely difficult to achieve. So if we’re just dependent on unit-tests and static analysis, we’re still missing defects.
The result is that we’re stuck combining multiple defect discovery methods if we want to avoid releasing defective software. The more methods we combine and the more we invest in continuously improving those methods, the fewer defects that will escape into the final product.
Some methods for checking work: personal code reviews against a maintained checklist, peer code reviews, formal code inspections, compilers, static analysis tools, unit tests, integration tests, smoke tests, performance tests, etc.
4.3. Unite fragmented knowledge
Relevant knowledge about a project is typically spread throughout an organization. Often, our software projects are required to bring together this knowledge to create some useful end product.
As a corollary to (4.1), we’ll tend to forget this knowledge if we rely on our memory alone to record it. If we operate this way for too long, this can mean that every new project requires finding out the same facts over and over again, lengthening cycle times unnecessarily and putting every project at risk of missing crucial details should it fail to rediscover them.
As a corollary to (4.2), the information we gather tends to have errors. Therefore, we also need to shop it around for review to ensure we’ve captured and understood the details well enough to get to work.
Outside of these two concerns, which typically apply in the early stages of a project, we also have to think about uniting fragmented knowledge during the project. This is typically achieved by holding regular status update meetings, tracking our progress, and attempting to identify issues as early as possible.
Some methods for uniting fragmented knowledge: Requirements elicitation and documentation, architecture documentation, status update meetings, software documentation, use cases, pair programming
4.4. Manage risk
Finally, we need some way to head off avoidable problems early. Very few software projects are without some risk – whether those are legal risks, budget risks, schedule risks, analysis paralysis risks, or other risks. Not managing these risks means that you could be investing time and money into the wrong product, a defective product, a late product, or a legal/financial fiasco.
As a consequence of (4.1), you’ll want to document and track the risks you identify as well as their mitigants to avoid having risks fall through the cracks.
As a consequence of (4.2), you’ll want to make sure your risk mitigation strategies are reviewed by the necessary parties to ensure they are complete and correct.
Finally, as a consequence of (4.3), you’ll want to involve as many parties as reasonable in the risk identification process. This will ensure that you have the best and most complete knowledge about the risks your project faces from multiple different perspectives.
Some methods for risk mitigation: Risk list, Risk management plan, Software Risk Evaluation (SRE), Continuous Risk Management (CRM), Fishbone / Ishikawa diagrams, Software estimation, Earned value schedule tracking, Requirements elicitation and documentation, architecture documentation
5. Conclusion
The traditional conversation about software process is hopelessly shallow so long as it views process as either a solved problem or an uninteresting one. Viewing it as a solved problem prevents us from exploring and benefiting from the rich history of software process. Viewing it as an uninteresting one prevents our teams and organizations from from operating at their peak because we don’t consider investigation and experimentation with methods to be worth our time.
I’ve attempted to get at the essential problems addressed by software processes and ignore their accidental solutions in specific processes. Specific processes will come and go, but these fundamental error sources are with us for the foreseeable future. The hope is that we can stop getting dragged into cargo cults and instead begin to evaluate, develop, and tailor processes based on our needs.
As an exercise for the intrigued reader, I’d recommend identifying a failure mode that has frustrated you. Next, identify a technique designed to help mitigate that failure. Bonus points if you choose a technique that scares you or one that seems stuffy or overly formal. Finally, try that technique out on an upcoming project.
For example, if bugs are an issue for you, try creating and reviewing your own code with a checklist. Let me know how it goes!
If you practice this a few times you should start to find unexpected methods and tools that are actually useful. Software process is a buffet of solutions for the problems you’re having right now. Dip in a try some things out! If you can’t find something to meet your needs, invent it and then share it with the rest of us so we can all benefit.
As I began writing this I realized that this is really a series of essays that have been brewing for some time. In Part II I’ll look at what we left out – phases and the ordering of events in a project. Finally, in Part III I’ll make this more concrete by applying what we’ve learned along the way to two fictional projects.

